pandas读写数据操作拓展
读写exce文件
Excel文件也是比较常见的用于存储数据的方式,它里面的数据均是以二维表格的形式显示的,可以对数据进行统计、分析等操作。Excel的文件扩展名有xls和xlsx两种。
Pandas中提供了对Excel文件进行读写操作的方法,分别为to_excel()方法和 read_excel()函数,关于它们的操作具体如下:
使用 to_excel()方法写入Exce文件
to_excel()方法的功能是将 Dataframe对象写入到 Excel工作表中,该方法的语法格式如下:
1 | to_excel(excel_writer, |
上述方法中常用参数表示的含义如下:
(1)excel_writer: 表示读取的文件路径
(2)sheet_name: 表示工作表的名称,可以接收字符串,默认为“ Sheet1”
(3)na_rep: 表示缺失数据
(4)index: 表示是否写行索引,默认为True
为了能够让大家更好地理解,接下来,创建一个2行2列的Dataframe对象,之后将该对象写入到itcast.xlsx文件中,具体代码如下:
1 | import pandas as pd |
1 | df1.to_excel('./data/itcast.xlsx', 'python基础班') |
tips: 如果写入的文件不存在,则系统会自动创建一个文件,反之则会将原文中的内容进行覆盖。
使用 read_excel()函数读取Exce文件
- read_excel()函数的作用是将 Excel文件中的数据读取出来,并转换成 Dataframe对象,其语法格式如下:
1 | read_excel(io, sheet_name=0) |
上述函数中常用参数表示的含义如下:
(1)io: 接收字符串,表示路径对象。
(2)sheet_name: 指定要读取的工作表,可接收字符串或int类型,
字符串指工作表名称,
int类型指工作表的索引。
接下来,通过 read_excel()函数将 itcast.xlsx文件中的数据全部读取出来,示例代码如下:
1 | data = pd.read_excel("./data/itcast.xlsx") |
读写数据库
大多数情况下,海量的数据是使用数据库进行存储的,这主要是依赖于数据库的数据结构化、数据共享性、独立性等特点。因此,在实际生产环境中,绝大多数的数据都是存储在数据库中。
Pandas支持 MySQL、Oracle、SQlite等主流数据库的读写操作。
为了高效地对数据库中的数据进行读取,这里需要引入SQLAIchemy。SQLAIchemy是使用Python编写的一款开源软件,它提供的SQL工具包和对象映射工具能够高效地访问数据库。
安装方式:
1 | pip3 install sqlalchemy |
在使用 SQLAlchemy时需要使用相应的连接工具包,比如Mysql需要安装mysqlconnector,Oracle则需要安装cx_Oracle。
- 在连接 MySQL数据库时,这里使用的是mysqlconnector驱动,如果当前的Python环境中没有该模块,则需要使用 python -m pip install mysql-connector 命令安装该模块。
下面以read_sql() 函数和to_sq() 方法为例: 分别向大家介绍如何读写数据库中的数据,具体内容如下。
使用 read_sql()函数读取数据
read_sql()函数既可以读取整张数据表,又可以执行SQL语句,其语法格式如下:
1 | pandas.read_sql(sql, con, |
上述函数中常用参数表示的含义如下:
(1)sql: 表示被执行的sql语句
(2)con: 接收数据库连接,表示数据库的连接信息
(3)index_col: 默认为None,如果传入一个列表,则表示为层次化索引
(4)params: 传递给执行方法的参数列表,如params={‘mame’: ‘vale’}
(5)columns: 接收list 表示读取数据的列名,默认为None
如果发现数据中存在空值,则会使用NaN进行补全。
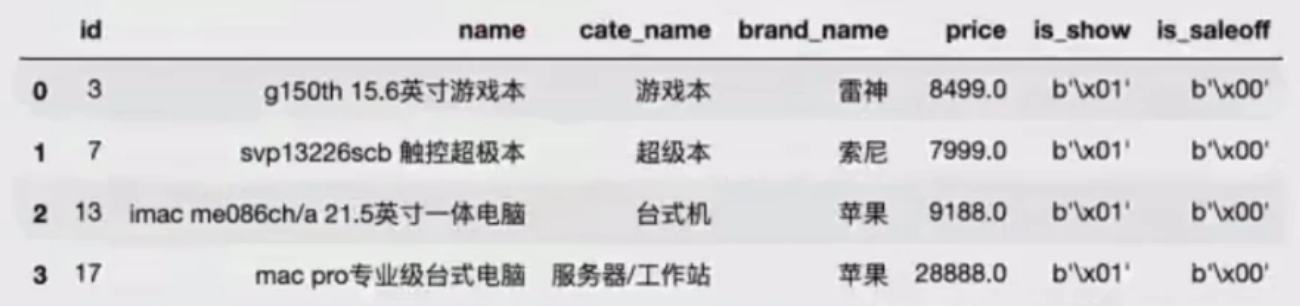
假设在MySQL数据库有一张数据表,该表中的内容如下图所示:

接下来,通过一个示例来演示如何使用read_sql()函数读取数据库中的数据表 goods,示例代码如下:
1 | import pandas as pd |
上述示例中,通过 create_engine()函数创建连接数据库的信息,调用read_sql() 函数读取数据库中的goods数据表,并转换成DataFrame对象。
注意: 在使用 create_engine函数创建连接时,其格式如下: “数据库类型+数据库驱动名称://用户名密码@机器地址/数据库名”。
read_sql()函数还可以执行一个SOL语句
例如,从goods数据表中第选出price值大于3的全部数据,具体的SQL语句如下:
1 | engine = create_engine('mysql+pymysql://root:[email protected]/jing_dong') |
根据上述SQL语句来读取数据库里面的数据,并将执行后的结果转换成DataFrame对象,示例结果如下:
需要强调的是,这里的SQL语句不仅是用于筛选的SQL语句,其他用于增删改查的SQL语句都是可以执行的。
使用to_sql()方法将数据写入到数据库中
to_sql()方法的功能是将 Series或 Dataframe对象以数据表的形式写入到数据库中,其语法格式如下:
1 | to_sql(name, con, |
上述方法中,参数所表示的含义如下所示。
(1)name: 表示数据库表的名称。
(2)con: 表示数据库的连接信息。
(3)if_exists: 可以取值为fail、replace或append,默认为fail,每个取值代表的含义如下:
fail: 如果表存在,则不执行写入操作。
replace: 如果表存在,则将源数据库表删除再重新创建。
append: 如果表存在,那么在原数据库表的基础上追加数据。
(4)index: 表示是否将 DataFrame行索引作为数据传入数据库,默认为True。
 微信
微信 支付宝
支付宝