pandas高级使用
如何处理nan
获取缺失值的标记方式(NaN或者其他标记方式)
如果缺失值的标记方式是NaN
判断数据中是否包含NaN:
pd.isnull(df)
pd.notnull(df)
存在缺失值nan:
1、删除存在缺失值的: dropna(axis=’rows’)
- 注: 不会修改原数据,需要接受返回值
2、替换缺失值: fillna(value, inplace=True)
value:替换成的值
inplace: True: 会修改原数据,False: 不替换修改原数据,生成新的对象
如果缺失值没有使用NaN标记,比如使用“?”
- 先替换“?”为np.nan,然后继续处理
电影数据的缺失值处理
- 电影数据文件获取
1 | # 读取电影数据 |
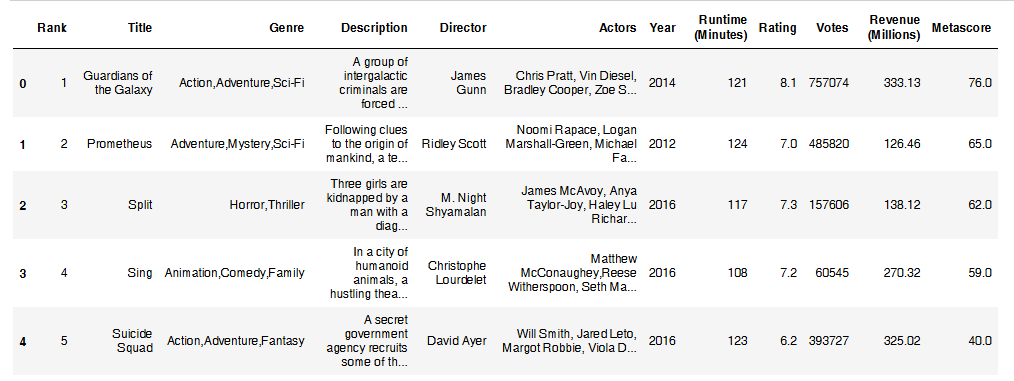
判断缺失值是否存在
- pd.notnull()
1 | pd.notnull(movie) |
- pd.isnull()
存在缺失值nan,并且是np.nan
- 1、制除
pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
1 | # 不修改原数据 |
- 2、替换缺失值
1 | # 替换存在缺失值的样本的两列 |
替换所有缺失值:
1 | for i in movie.columns: |
不是缺失值nan,有默认标记的
数据是这样的:
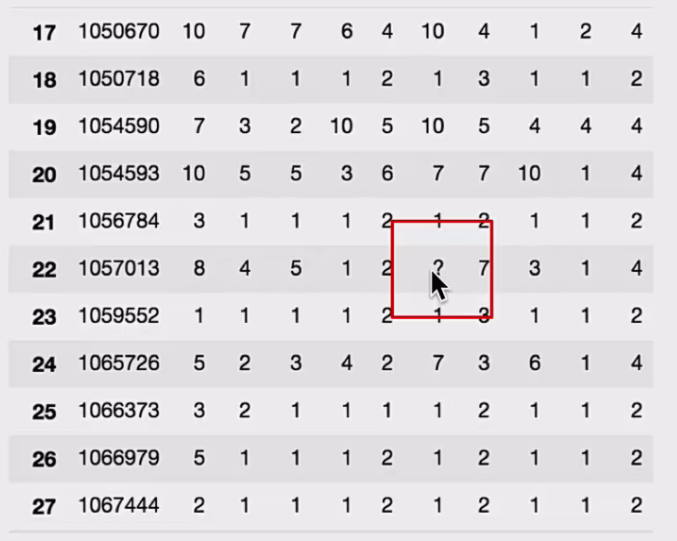
1 | wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data") |
以上数据在读取时,可能会报如下错误:
1 | URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed... |
解决办法:
1 | # 全局取消证书验证 |
处理思路分析:
1、先替换“?”为np.nan
df.replace(to_replace=, value=)
to_replace: 替换前的值
value: 替换后的值
1 | # 把一些其它值标记的缺失值,替换成np.nan |
- 2、在进行缺失值的处理
1 | # 删除 |
离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
数据的离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值。
离散化有很多种方法,这使用一种最简单的方式去操作:
原始人的身高数据: 165, 174, 160, 180, 159, 163, 192, 184
假设按照身高分几个区间段: 150~ 165, 165~ 180, 180~ 195
这样我们将数据分到了三个区间段,我可以对应的标记为矮、中、高三个类别,最终要处理成一个“哑变量”矩阵。
股票的涨跌幅离散化
我们对股票每日的“p_change”进行离散化:
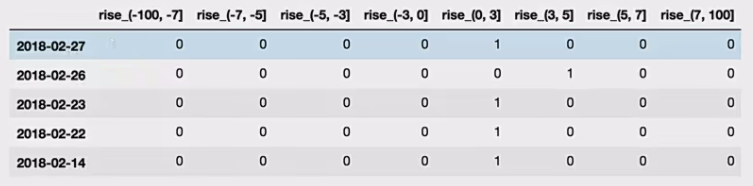
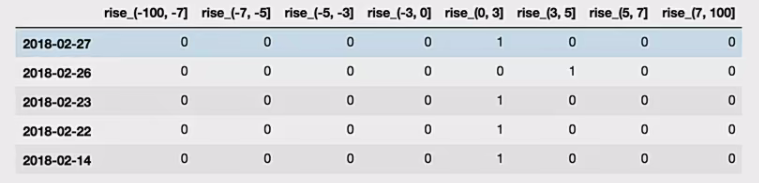
读取股票的数据
先读取股票的数据,筛选出p_change数据
1 | data = pd.read_csv("./data/stock_day.csv" ) |
将股票涨跌幅数据进行分组
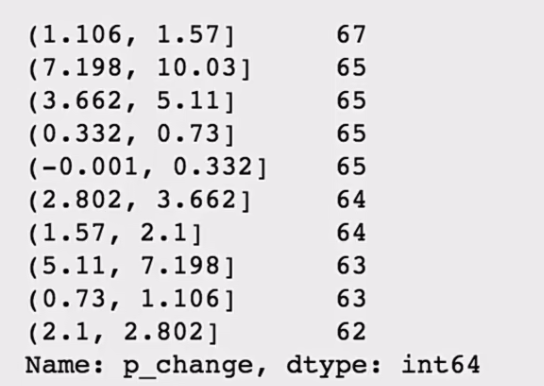
使用的工具:
pd.qcut(data, q):
对数据进行分组将数据分组,一般会与value_counts搭配使用,统计每组的个数
series.value_counts(): 统计分组次数
1 | # 自行分组 |
自定义区间分组:
- pd.cut(data, bins)
1 | # 自己指定分组区间 |
股票涨跌幅分组数据变成one-hot编码
- 什么是one-hot编码
把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1。其又被称为热编码。
把下图中左边的表格转化为使用右边形式进行表示:
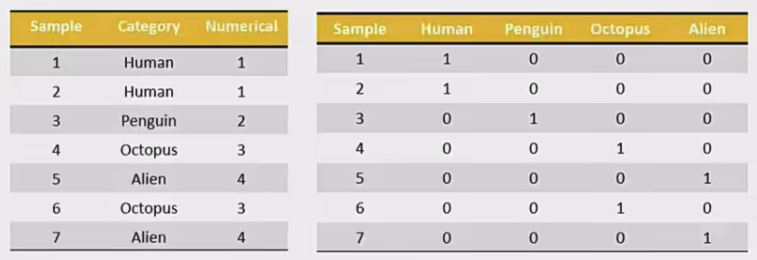
pandas.get_dummies(data, prefix=None)
data: array-like, Series, or DataFrame
prefix: 分组名字
1 | # 得出one-hot编码矩阵 |
pd.concat实现数据合并
pd.concat([data1, data2], axis=1)
- 按照行或列进行合并,axis=0为列索引,axis=1为行索引
比如我们将刚才处理好的one-hot编码与原数据合并
1 | # 按照行索引进行 |
pd.merge
pd.merge(left, right, how=’inner’, on=None)
可以指定按照两组数据的共同键值对合并或者左右各自
left: DataFrame
right: 另一个DataFrame
on: 指定的共同键
how: 按照什么方式连接
| Merge method | SQL Join Name | Description |
|---|---|---|
| left | LEFT OUTER JOIN | Use keys from left frame only |
| right | RIGHT OUTER JOIN | Use keys from right frame only |
| outer | FULL OUTER JOIN | Use union of keys from both frames |
| inner | INNER JOIN | Use intersection of keys from both frames |
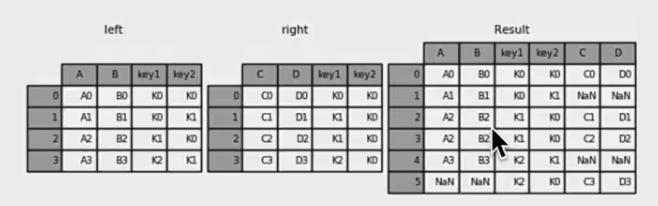
pd.merge合并
1 | left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], |
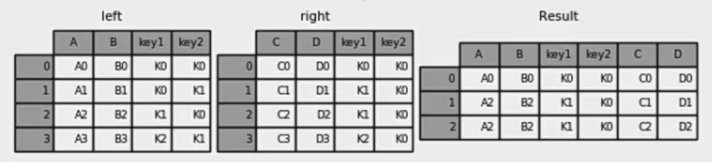
- 右连接
1 | result = pd.merge(left, right, how='right', on=['key1', 'key2']) |
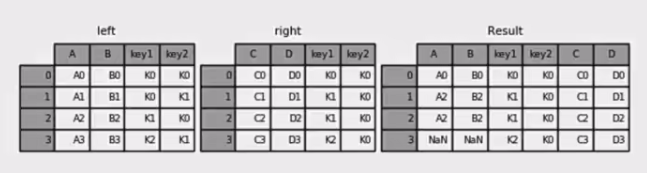
- 外链接
1 | result = pd.merge(left, right, how='outer', on=['key1', 'key2']) |
交叉表与透视表的作用
探究股票的涨跌与星期几有关?
以下图当中表示,week代表星期几,1、0代表这一天股票的涨跌幅是好还是坏,里面的数据代表比例。
可以理解为所有时间为星期一等等的数据当中涨跌幅好坏的比例。

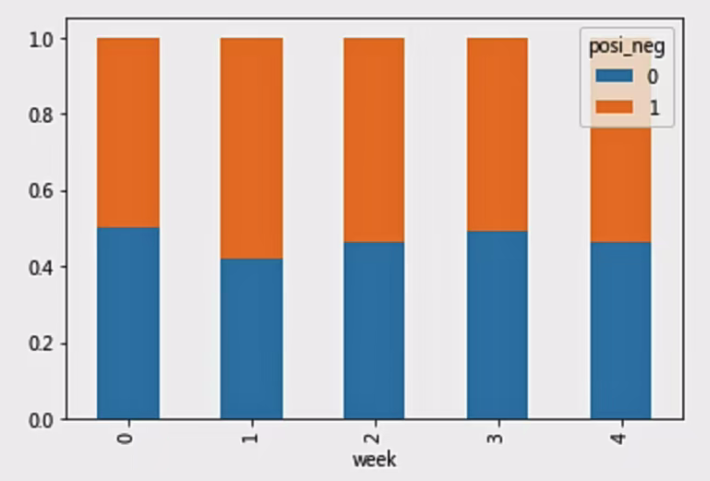
交叉表: 交叉表用于计算一列数据对于另外一列数据的分组个数(用于统计分组频率的特殊透视表)
- pd.crosstab(value1, value2)
透视表: 透视表是将原有的DataFrame的列分别作为行索引和列索引,然后对指定的列应用聚集函数。
data.pivot_table()
DataFrame.pivot_table([], index=[])
案例分析
数据准备
准备两列数据,星期数据以及涨跌幅是好是坏数据
进行交叉表计算
1 | # 寻找星期几跟股票张得的关系 |
但是我们看到count只是每个星期日子的好坏天数,并没有得到比例,该怎么去做?
- 对于每个星期一等的总天数求和,运用除法运算求出比例
1 | # 算数运算,先求和 |
查看效果
使用plot画出这个比例,使用stacked的柱状图
1 | pro.plot(kind='bar', stacked=True) |
使用pivot_table(透视表)实现
使用透视表,刚才的过程更加简单
1 | # 通过透视表,将整个过程变成更简单一些 |
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况
想一想其实刚才的交叉表与透视表也有分组的功能,所以算是分组的一种形式,只不过他们主要是计算次数或者计算比例!!看其中的效果:
分组与聚合
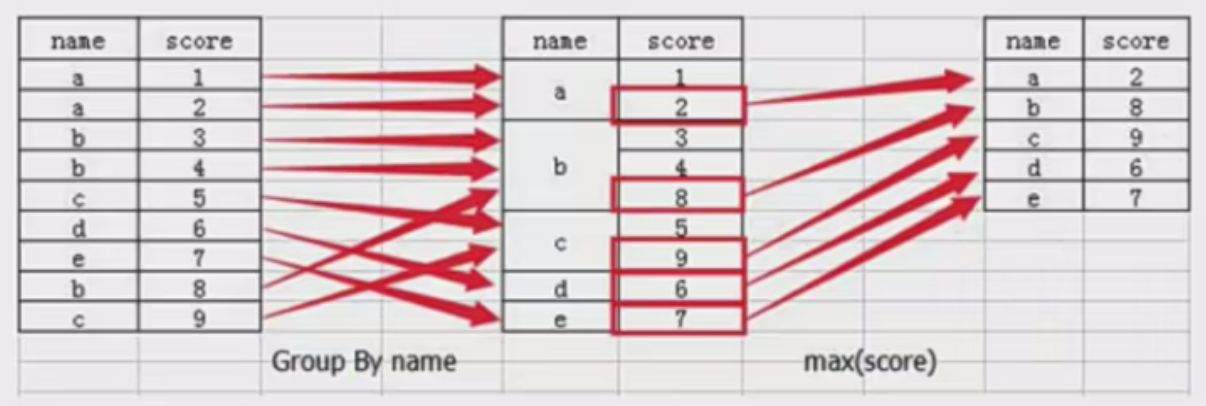
分组API
DataFrame.groupby(key, as_index=False)
- key: 分组的列数据,可以多个
案例: 不同颜色的不同笔的价格数据
1 | col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]}) |
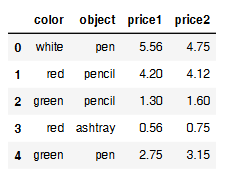
- 进行分组,对颜色分组,price进行聚合
1 | # 分组,求平均值 |
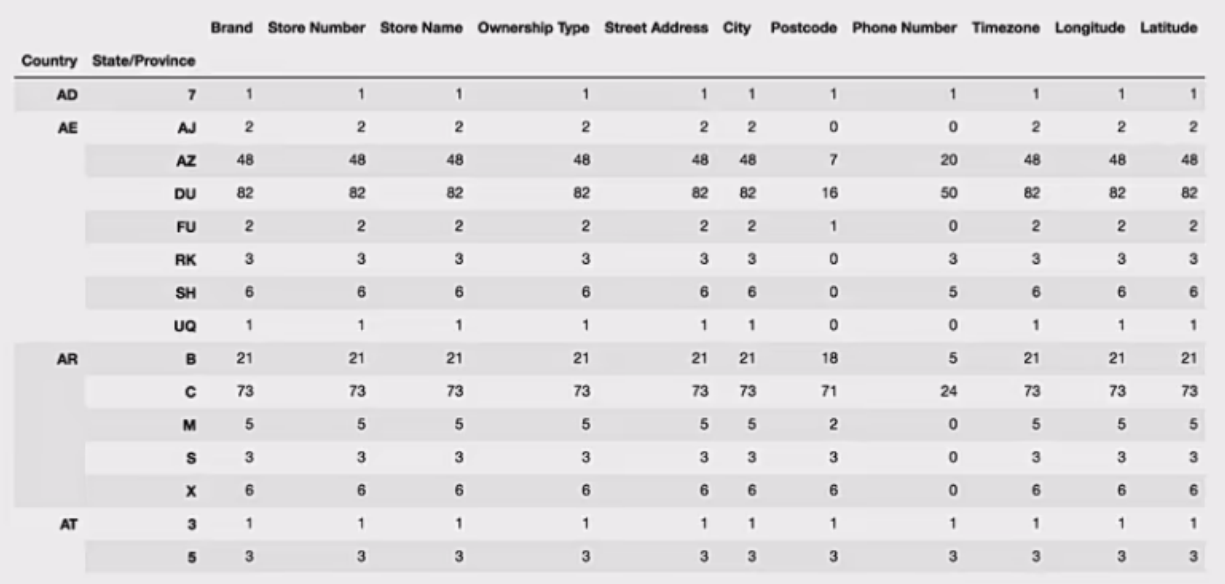
星巴克零售店铺数据
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
数据获取
从文件中读取星巴克店铺数据
1 | # 导入星巴克店的数据 |
进行分组聚合
1 | # 按照国家分组,求出每个国家的星巴克零售店数量 |
画图显示结果:
1 | count['Brand'].plot(kind='bar', figsize=(20, 8)) |

假设我们加入省市一起进行分组
1 | # 设置多个索引,set_index() |
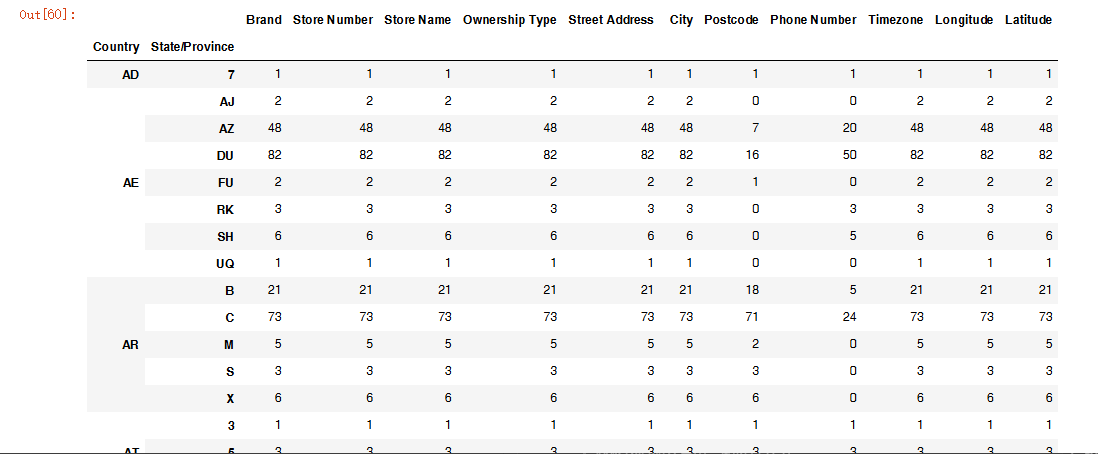
仔细观察这个结构,与我们前面讲的哪个结构类似??
与前面的Multilndex结构类似
需求
现在我们有一组从2006年到2016年1000部最流行的电影数据
数据来源: https://www.kaggle.com/damianpanek/sunday-eda/
- 问题1: 我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
- 问题2: 对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
- 问题3: 对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
实现
首先获取导入包,获取数据
1 | %matplotlib inline |
1 | #文件的路径 |
问题一:
我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
- 得出评分的平均分
使用mean函数
1 | df ["Rating"].mean( ) |
- 得出导演人数信息
求出唯一值,然后进行形状获取
1 | ## 导演的人数 |
问题二:
对于这一组电影数据,如果我们想Rating,Runtime(Minutes)的分布情况,应该如何呈现数据?
- 直接呈现,以直方图的形式
选择分数列数据,进行plot
1 | df["Rating"].plot(kind='hist', figsize=(20, 8)) |
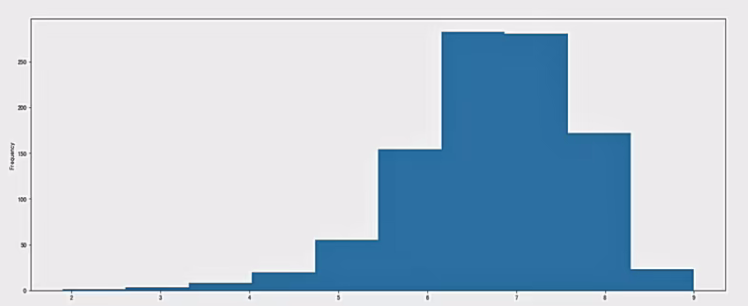
- Rating进行分布展示
进行绘制直方图
1 | plt.figure(figsize=(20, 8), dpi=80) |
修改刻度的间隔
1 | # 求出最大最小值 |
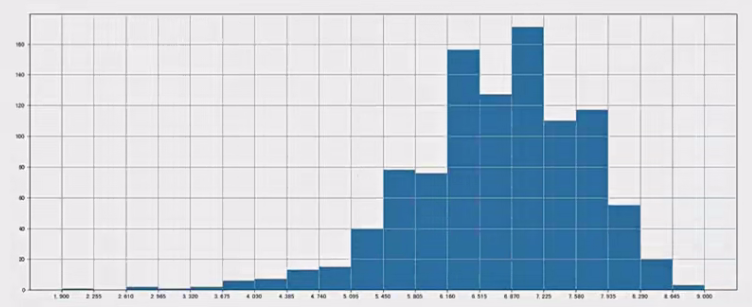
- Runtime(Minutes)
1 | # Runtime (Minutes)分布 |
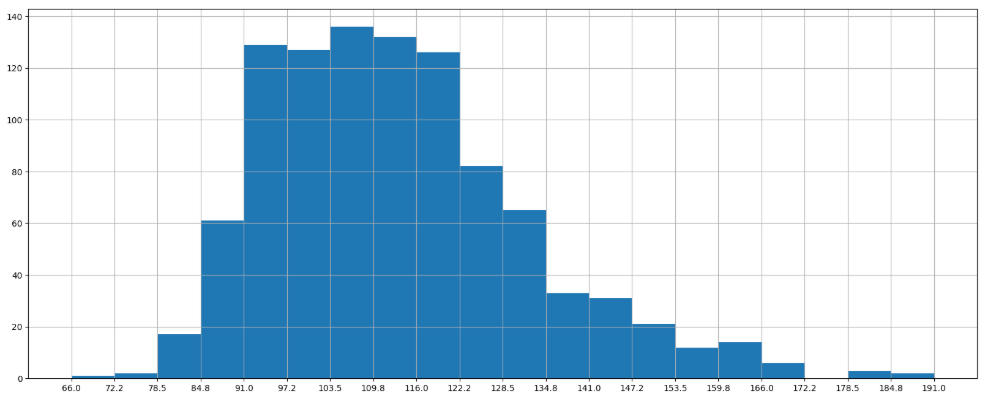
进行绘制直方图
问题三:
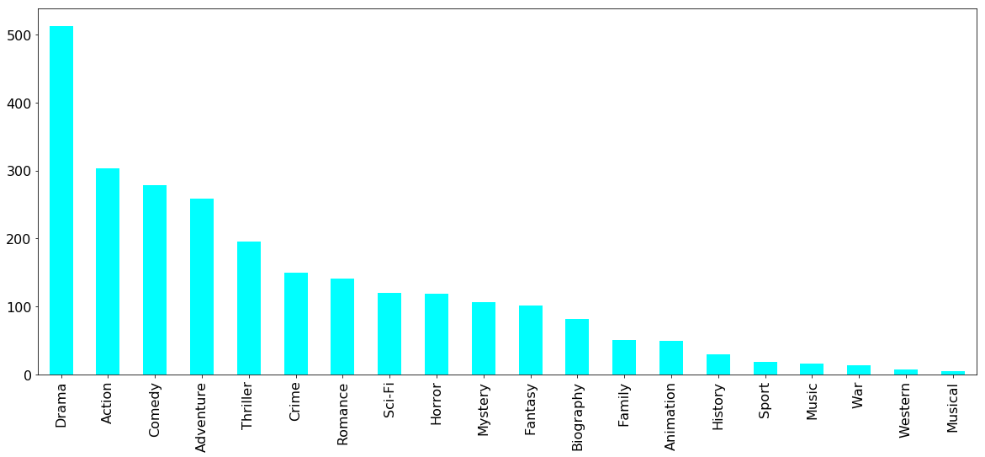
对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
思路分析
思路
1、创建一个全为0的dataframe,列索引置为电影的分类,temp_df
2、遍历每一部电影,temp_df中把分类出现的列的值置为1
3、求和
1、创建一个全为0的dataframe,列索引置为电影的分类,temp_df
1 | # 进行字符串分割 |
- 2、遍历每一部电影,temp_df中把分类出现的列的值置为1
1 | for i in range(1000): |
- 3、求和,绘图
1 | temp_df.sum().sort_values(ascending=False).plot(kind="bar",figsize=(20,8),fontsize=20,colormap="cool") |
 微信
微信 支付宝
支付宝