

落叶繁华品牌设计
品牌故事生命,本就是一段最精彩的旅行, 因为生命的真谛,就是永远在路上。 寻觅本心,用香味承载最美的时光故事, 一直在路上,与不负韶华的走下去。
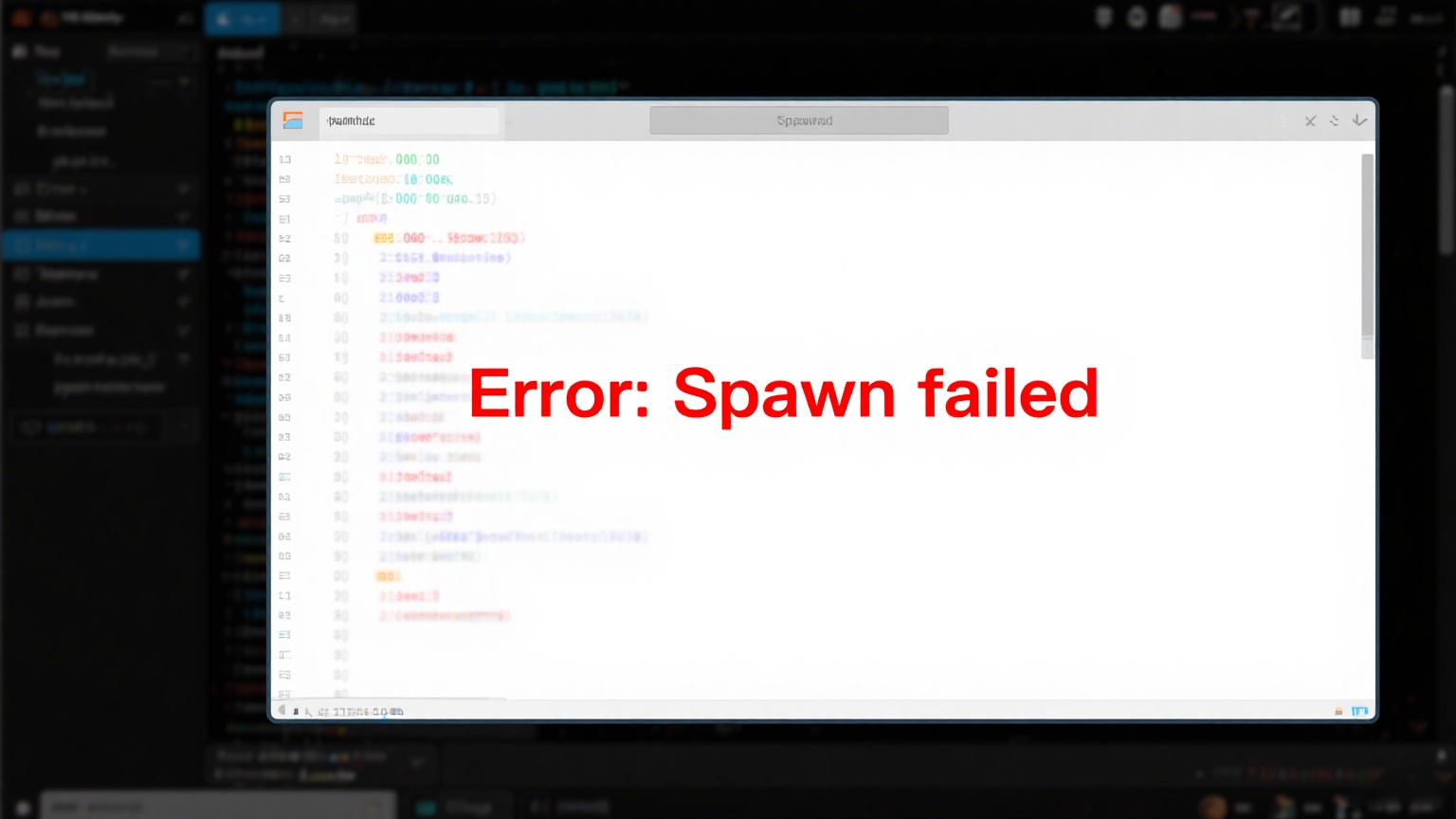
hexo+butterfly提交GitHub过程中出现Error:Spawn failed
hexo+butterfly提交GitHub过程中出现Error:Spawn failed,该如何解决?如图所示: 使用GitHub的443端口22端口可能被防火墙屏蔽了,可以尝试连接GitHub的443端口。 这个解决方案的思路是:给~/.ssh/config文件里添加如下内容,这样ssh连接GitHub的时候就会使用443端口。如果~/.ssh目录下没有config文件,手动新建一个即可。 123Host github.com Hostname ssh.github.com Port 443 验证是否成功修改完~/.ssh/config文件后,使用ssh -T [email protected]来测试和GitHub的网络通信是否正常。 123456$ ssh -T [email protected] authenticity of host '[ssh.github.com]:443 ([20.205.243.160]:443)' can't be established.ED25519 key fingerprint is...

PicGo+GitHub(图床)的使用
1、首先下载PicGo https://molunerfinn.com/PicGo/ 2、进入PicGo-图床设置-GitHub-GitHub设置 设置自定义域名: 可加速:https://cdn.jsdelivr.net/gh/LUCKYLIYONGHHUI/picture@main 设定Token获得方法: 登录 Github 后,点击“右上角头像->Settings”,进入用户设置界面(个人建议单独建一个库,专门用来放图片) 然后点击左侧边栏的 “Developer Settings” 选项,配置 Github API Key(即 token) 记得是点击Tokens(classic),选择Generate new Token-Generate new token(classic) 设置 token,如下图所示:设置令牌名称(Note)、到期时间(Expiration)、可访问的权限范围(Select scopes),然后保存即可 记得点击完Generate...

Hexo Butterfly背景板透明
创建css文件,书写样式在blog根目录找到source/css(没有就新建一个),再在css文件夹中新建一个transparent.css文件,写入 1234567891011121314151617/*文章页面*/.layout>#post{ background: transparent !important; /* 页面透明 */ background: rgba(0, 0, 0, 0.3); /* 卡片背景为白色透明度为0.3 */ backdrop-filter: blur(3px); /* 添加毛玻璃效果 */}/*分类页面*/.layout>#page{ /* background: rgba(0, 0, 0, 0.15); */ /* 背景为白色透明度为0.15 */ background: transparent !important; /* 页面透明 */}/*侧边栏页面*/#aside-content>.card-widget { background:...

Hexo Butterfly图库设置
新建图库页面首先,前往你的 Hexo 博客的根目录,在 Hexo 博客根目录 [blog]下打开终端或者在vscode控制台中,输入 1hexo new page sucaiku 修改相关参数找到 source/sucaiku/index.md 这个文件,并修改这个文件,记得添加 type: “sucaiku” 123456---title: 素材库date: 2025-05-13 15:22:41type: "sucaiku"aside: false--- 然后再在该页面(文件里)添加一下代码 1234<div class="gallery-group-main">{% galleryGroup '壁纸' '收藏的一些壁纸' '/paper' https://i.loli.net/2019/11/10/T7Mu8Aod3egmC4Q.png %}{% galleryGroup '漫威'...
Fiddler基本使用
fiddler的核心作用 接口测试 发送自定义的请求,模拟小型接口测试 定位前后端bug 抓取协议包,前后端联调 弱网测试 模拟限速操作,弱网,断网 构建模拟测试场景 数据篡改,重定向 前端性能分析及优化 fiddler的工作原理 本地应用与服务器之间的所有请求(request)和响应(response),由fiddler进行转发,此时fiddler以代理服务器的方式存在 由于所有的网络数据都需要经过fiddler,因此,fiddler能够截取数据信息,实现网络数据抓包 fiddler和F12抓包对比 相同点: 都可以对http和https请求进行抓包分析 不同点: F12无法抓取app端的请求,而fiddler工具可以完成 F12无法修改请求数据,请求之前和请求之后,而fiddler工具可以完成 F12可以在console控制台输入部分命令,方便查看前端的数据信息,可以通过application上面查看一些请求的数据,尤其是涉及到登录或者邀请相关的知识 fiddler基本功能使用导包 File - Export...
Seaborn案例分析
本文将租房网站上北京地区的租房数据作为参考,运用前面所学到的数据分析知识,带领大家一起来分析真实数据,并以图表的形式得到以下统计指标: (1)统计每个区域的房源总数量,并使用热力图分析房源位置分布情况 (2)使用条形图分析哪种户型的数量最多、更受欢迎 (3)统计每个区域的平均租金,并结合柱状图和折线图分析各区域的房源数量和租金情况 (4)统计面积区间的市场占有率,并使用饼图绘制各区间所占的比例 基本数据介绍将爬到的数据下载到本地,并保存在“链家北京租房数据.csv”文件中,打开该文件后可以看到里面有很多条(本案例爬取的数据共计8224条)信息,具体如下图所示: 数据读取准备好数据后,我们便可以使用 Pandas读取保存在CSV文件的数据,并将其转换成DataFrame对象展示便于后续操作这些数据。 首先,读取数据: 123456import pandas as pdimport numpy as np# 读取链家北京租房信息file_data =...
Seaborn分类数据绘图
数据集中的数据类型有很多种,除了连续的特征变量之外,最常见的就是类别型的数据了,比如人的性别、学历、爱好等,这些数据类型都不能用连续的变量来表示,而是用分类的数据来表示。 Seaborn针对分类数据提供了专门的可视化函数,这些函数大致可以分为如下三种: 分类数据散点图: swarmplot()与 stripplot()。 类数据的分布图: boxplot()与 violinplot()。 分类数据的统计估算图: barplot()与 pointplot()。 类别散点图通过 stripplot()函数可以画一个散点图, stripplot0函数的语法格式如下。 1n.stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, jitter=False) 上述函数中常用参数的含义如下: (1)x,y,hue: 用于绘制长格式数据的输入。 (2)data: 用于绘制的数据集。如果x和y不存在,则它将作为宽格式,否则将作为长格式。 (3)jitter:...